
A M.Eng. student at Yantai University
Hi, guys👋! I'm Siqi Fu (符思琦)😊, currently a third-year master's student at Yantai University, majoring in Computer Technology under the supervision of Prof. Peng Song. Previously, I earned my bachelor's degree at Tianjin Foreign Studies University.
My current research focuses on speech emotion recognition (SER)🗣️ and multimodal emotion recognition (MER). I'm also interested in multi-view learning and EEG emotion recognition.
During my leisure time, I am interested in movies🎞️, music🎧️, photography📷️, and various sports🏃♀️~
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "👩🎓Education
-
 Yantai University (YTU)M.Eng. in Computer TechnologySep. 2023 - present
Yantai University (YTU)M.Eng. in Computer TechnologySep. 2023 - present -
 Tianjin Foreign Studies University (TJFSU)B.Eng. in Digital Media TechnologySep. 2019 - Jul. 2023
Tianjin Foreign Studies University (TJFSU)B.Eng. in Digital Media TechnologySep. 2019 - Jul. 2023
🏆️Honors & Awards
-
The First Prize Scholarship of YTU2024
-
The Second Prize Scholarship of TJFSU2022
-
The Second Prize Scholarship of TJFSU2021
-
National Encouragement Scholarship2020
Selected Publications (view all )
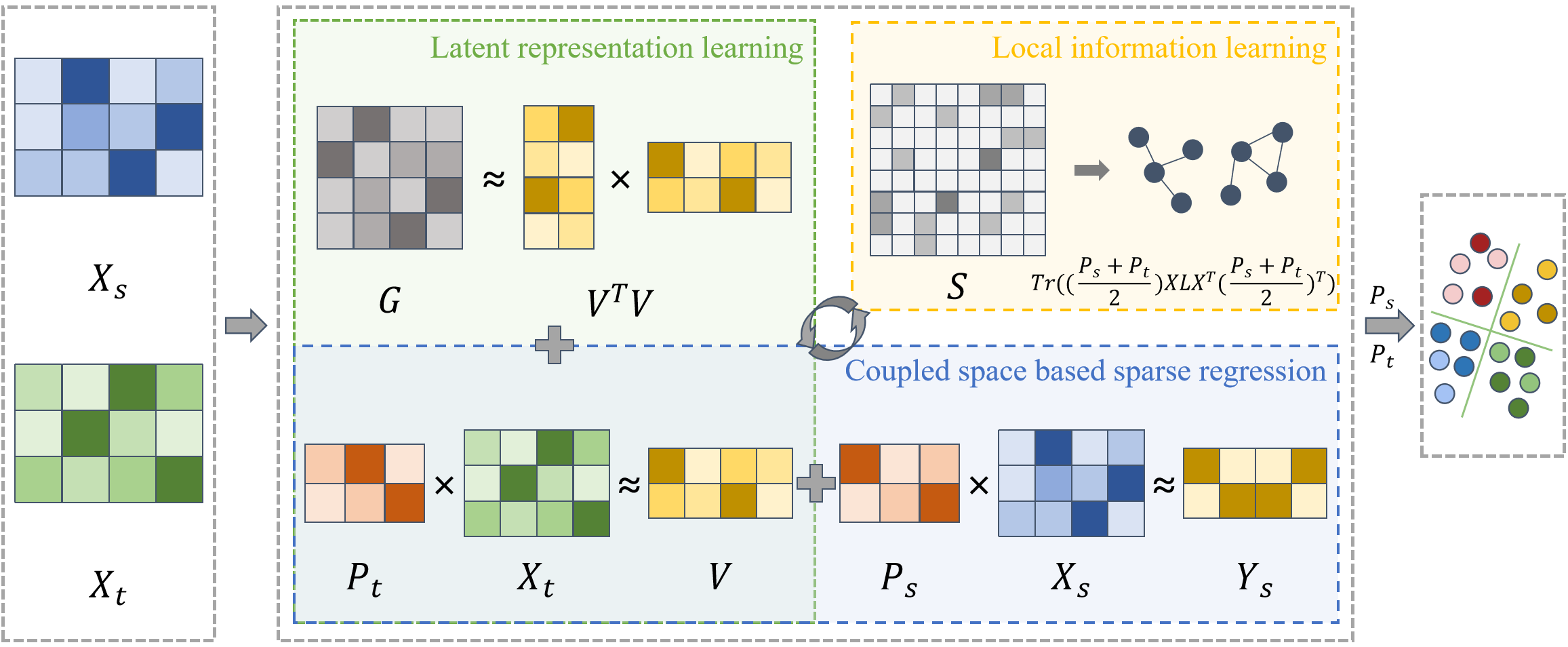
Coupled Sparse Subspace Alignment-Based Domain Adaptation for Speech Emotion Recognition
Siqi Fu, Peng Song, Wenming Zheng
IEEE Transactions on Computational Social Systems (TCSS) 2025
We propose a novel DA approach named coupled sparse subspace alignment (CSSA) for cross-domain SER. Specifically, CSSA first performs latent representation learning on the unlabeled target domain data, in which the latent representation matrix is then optimized into a pseudolabel matrix to provide emotional guidance. Meanwhile, it models the source and target domains separately by sparse regression, thereby learning both discriminative and domain-specific information. Subsequently, CSSA performs coupled subspace alignment to reduce the domain discrepancy, where the dual projection matrices are progressively aligned to enhance their similarity. Additionally, a graph Laplacian regularization is applied to the cross-domain data to capture the local geometric structure.
Coupled Sparse Subspace Alignment-Based Domain Adaptation for Speech Emotion Recognition
Siqi Fu, Peng Song, Wenming Zheng
IEEE Transactions on Computational Social Systems (TCSS) 2025
We propose a novel DA approach named coupled sparse subspace alignment (CSSA) for cross-domain SER. Specifically, CSSA first performs latent representation learning on the unlabeled target domain data, in which the latent representation matrix is then optimized into a pseudolabel matrix to provide emotional guidance. Meanwhile, it models the source and target domains separately by sparse regression, thereby learning both discriminative and domain-specific information. Subsequently, CSSA performs coupled subspace alignment to reduce the domain discrepancy, where the dual projection matrices are progressively aligned to enhance their similarity. Additionally, a graph Laplacian regularization is applied to the cross-domain data to capture the local geometric structure.
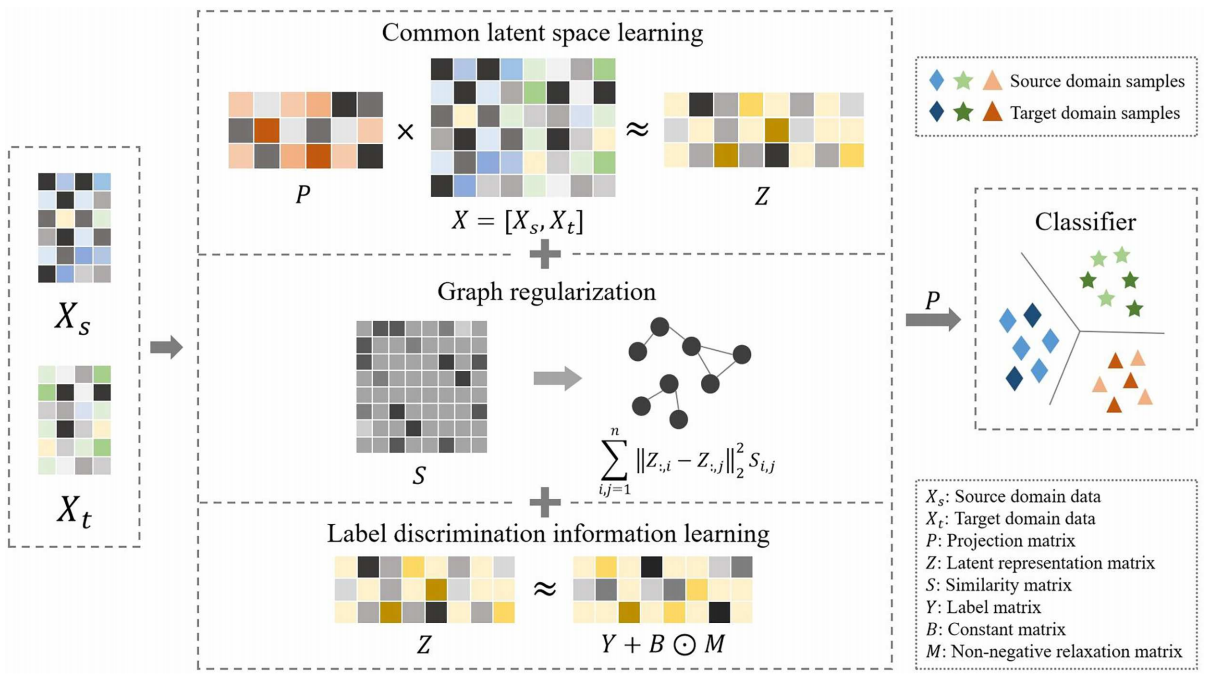
Common Discriminative Latent Space Learning for Cross-Domain Speech Emotion Recognition
Siqi Fu, Peng Song, Hao Wang, Zhaowei Liu, Wenming Zheng
IEEE Transactions on Computational Social Systems (TCSS) 2024
We present a novel common discriminative latent space learning (CDLSL) method for cross-domain SER. To be specific, we first obtain a common latent space by imposing a projection matrix on the cross-domain data. Meanwhile, we impose an uncorrelated constraint on the projection matrix to ensure that the features are representative and discriminative after dimension reduction. Then, we implement a graph regularization term on the latent representations of the samples to capture the local similarity information. Furthermore, to obtain a more discriminative common latent space, we introduce the label information by aligning the latent space with the relaxed label space, while mitigating the information loss for regression.
Common Discriminative Latent Space Learning for Cross-Domain Speech Emotion Recognition
Siqi Fu, Peng Song, Hao Wang, Zhaowei Liu, Wenming Zheng
IEEE Transactions on Computational Social Systems (TCSS) 2024
We present a novel common discriminative latent space learning (CDLSL) method for cross-domain SER. To be specific, we first obtain a common latent space by imposing a projection matrix on the cross-domain data. Meanwhile, we impose an uncorrelated constraint on the projection matrix to ensure that the features are representative and discriminative after dimension reduction. Then, we implement a graph regularization term on the latent representations of the samples to capture the local similarity information. Furthermore, to obtain a more discriminative common latent space, we introduce the label information by aligning the latent space with the relaxed label space, while mitigating the information loss for regression.